Stream Storage
Data sent from devices into the Spotflow IoT Platform is automatically stored in the stream storage. From here, you can use HTTP API to consume the data in their applications or data processing pipelines.
You can use stream storage to:
- Execute batch processing jobs on top of the stored data.
- Analyze the data with tools such as Apache Spark or Databricks.
- Provide backend for data-intensive applications.
- To keep long-term data backup.
Under the hood, the Stream Storage is an Azure Storage Account with two containers:
- The
messagescontainer - each message is always stored here as a single blob. - The
batchescontainer - optionally, multiple messages can be concatenated into larger units and stored here. This might improve the efficiency of your subsequent processing steps. Please see the Concatenation section for more details.
Check out also the Egress Sinks for other ways to consume data from the platform, which are more suitable for streaming/near-real-time scenarios, or Visualize Data for visualizing the data in the Grafana.
Messages in the messages container are stored in the following structure:
messages/<stream-group>/<stream>/<device-id>/<batch-id>/<message-id>

The following guarantees are provided:
- Messages are deduplicated based on the
message-idandbatch-idin the context of the combination of stream group, stream, and device. - The messages are written atomically. Partially written messages are not observable.
- The messages are immutable. Once written, they cannot be changed.
- Each message is stored in a separate blob.
- In most cases, data is available a few seconds after the platform receives it.
Please see the Sending data for more information on message-id and batch-id identifiers.
Data in different Workspaces is stored in different storage accounts to provide strong isolation and granular access control. Users with the most strict security requirements can also use their own Azure Storage Account for stream storage.
Concatenation
When many messages need to be processed at once, we recommend concatenating them into larger units. Without concatenation, reading each message requires a separate network round-trip. With concatenation, many messages can be read in a single network round-trip, which might significantly improve the processing speed, especially when the messages are small.
The platform can automatically concatenate messages from a single batch into a single blob.
This blob is then located in the batches container in the following structure:
batches/<stream-group>/<stream>/<device-id>/<batch-id>

Please see the Sending data for more information on the concept of batches.
Concatenation is disabled by default but can be enabled for each individual stream.
There are two mods you can choose from:
- Concatenation with new lines - Messages are concatenated with a new line character (
\n). This might be useful for messages containing data in naturally row-based formats, such as CSV or newline-delimited JSON. - Concatenation without new lines - Messages are concatenated as they are. The first byte of the following message is directly after the last byte of the previous message. This might be useful for self-delimited data formats, such as Protobuf with length-prefix.
The platform concatenates messages continuously at regular intervals, allowing you to read a batch blob even before it is fully completed.
You can adjust the interval's frequency by setting the max staleness property on the stream.
For example, if the value is set to 1 minute, the platform strives to ensure that all messages received more than 1 minute ago have already been concatenated into a batch blob.
By default, max staleness is set to 10 minutes.
If concatenation is disabled, no blobs are available in the batches container.
Whether the concatenation is enabled or not, the messages are always stored in the messages container as individual blobs.
For concatenation, the following guarantees are provided:
- Messages in the blob are deduplicated based on the
message-id. - New messages are appended atomically to the blob. Partially written messages are not observable.
- New messages are appended in the order they were received from the device.
- New messages are appended to the blob continuously, every few seconds.
- All messages from a single batch are stored in a single blob.
How to read data from Stream Storage
As described above, the stream storage is essentially an Azure Storage Account. You can use any tool that supports Azure Storage to read the data. We recommend using Azure Storage Explorer for this purpose.
Information necessary to access the stream storage is available in the Spotflow Portal.
Please see the following short guide on how to access the stream storage using Azure Storage Explorer:
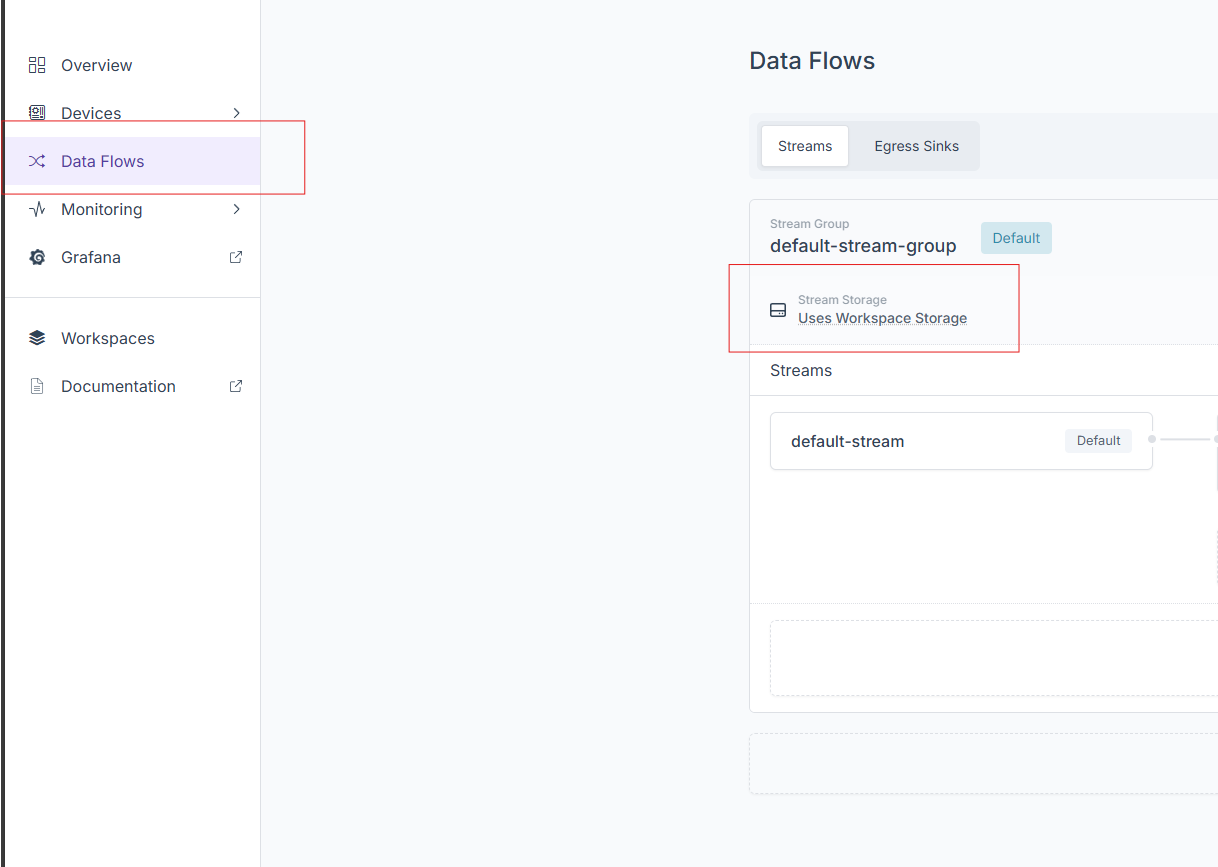
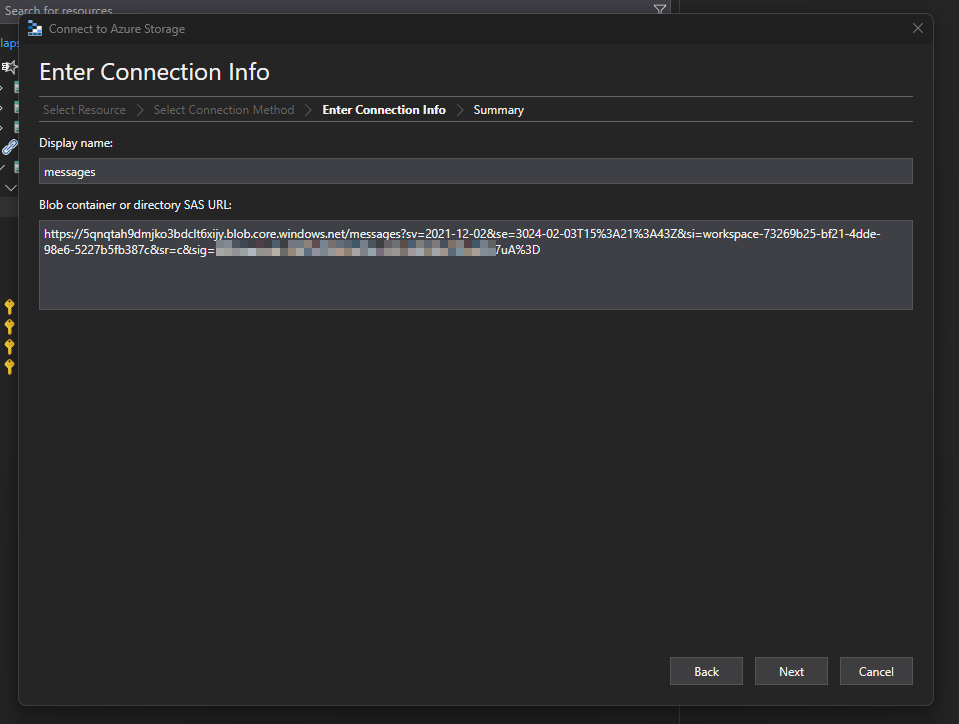
Navigate to the Data Flows and find the desired stream group. Click on its stream storage.
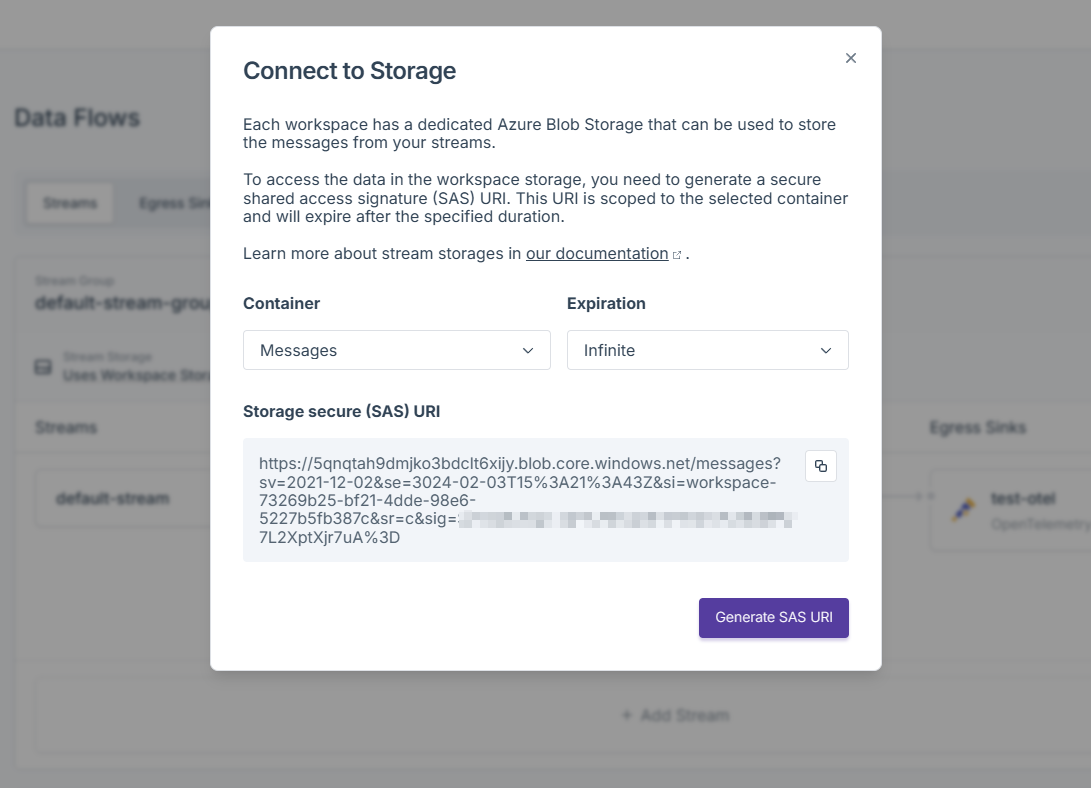
Select desired container (
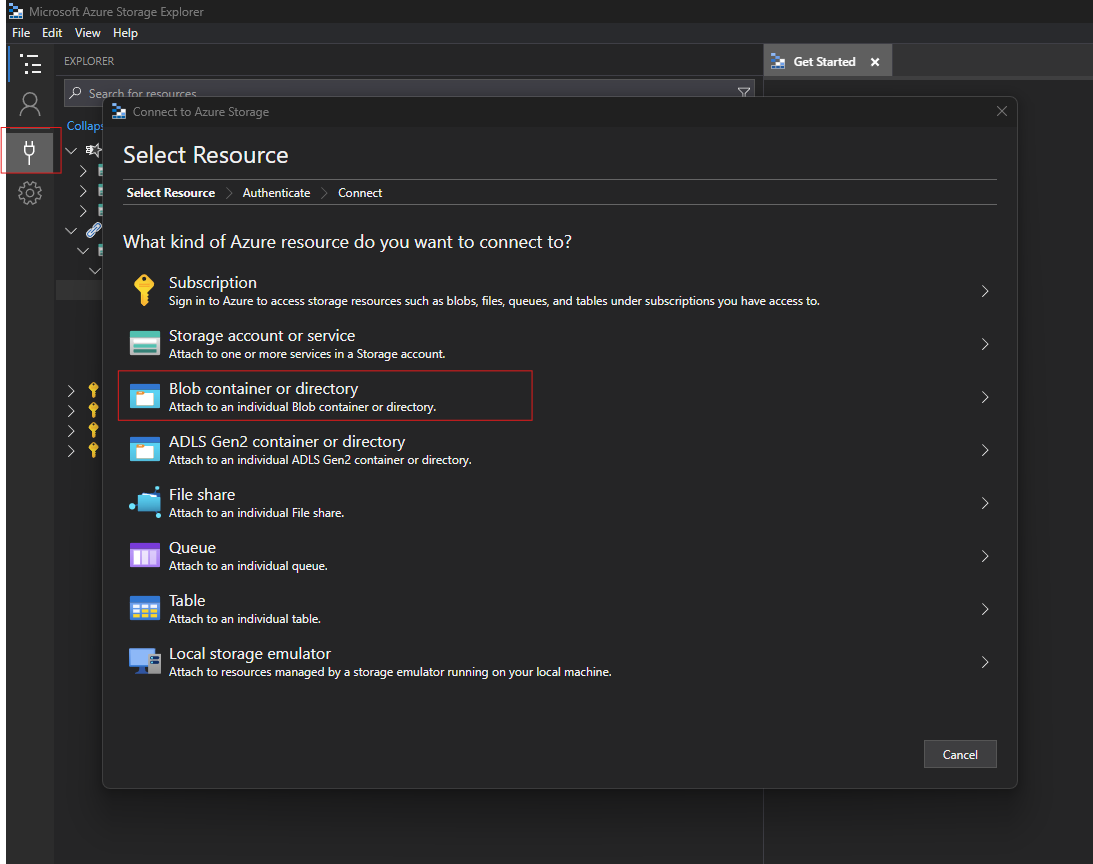
messagesorbatches). Copy the generated SAS URI.Download Azure Storage Explorer and attach the container.
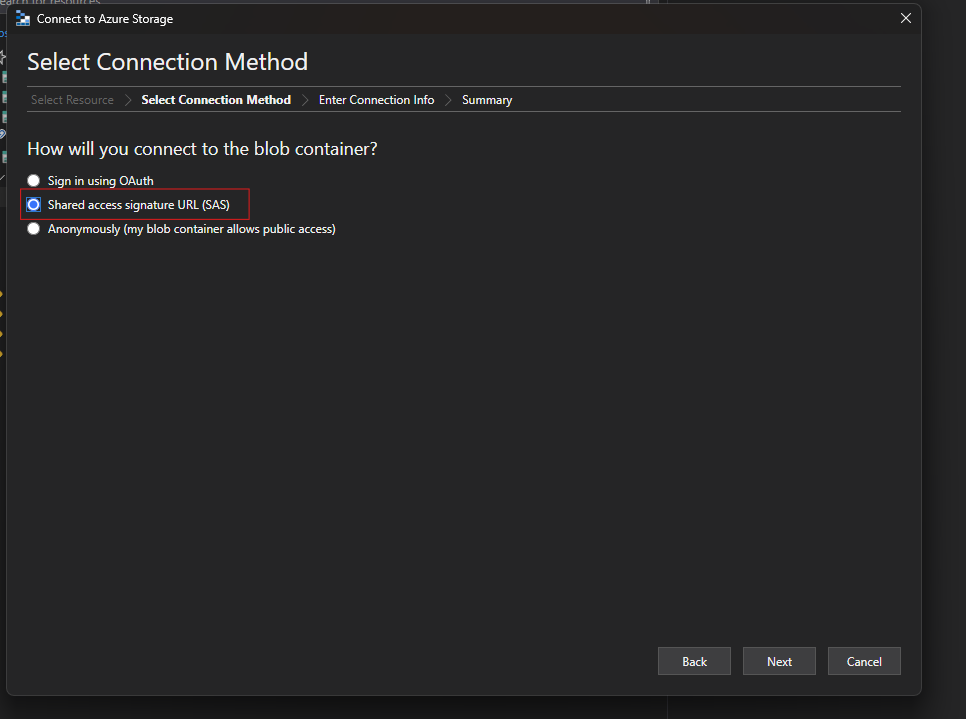
Use the
Shared access signature URL (SAS)option.Paste the previously copied SAS URI.
Explore the data in a similar way as on a file system.
Custom Storage Account
By default, the platform provides a storage account for each Workspace, which can be used by all its stream groups. This is the simplest way to store data without requiring additional configuration.
However, using the default storage account may not always be suitable, especially in the following cases:
- Encryption - Data must be encrypted using a specific key.
- Pre-existing storage account - Data needs to be stored in a pre-existing storage account.
- Specific storage account configuration - The underlying storage account needs to be configured in a specific way. Examples might include replication level, default access tier, firewall, capacity reservation, etc.
- Data residency - Data needs to be stored in a specific region.
In such cases, you can provide a custom storage account that you fully control. The platform will then use this storage account instead of the default one. You can assign a custom storage account to:
- A stream group - All streams in the group will use the custom storage account.
- A stream - Only the selected stream will use the custom storage account. It takes precedence over a custom storage account assigned to the parent stream group.
In both cases, you can specify a custom storage account when creating or updating a stream group or stream via Portal, CLI, or API. A connection string with Access Key is required.